- Privacy Policy
Home » Inferential Statistics – Types, Methods and Examples

Inferential Statistics – Types, Methods and Examples
Table of Contents
Inferential statistics is a branch of statistics that uses sample data to make generalizations, predictions, or inferences about a larger population. Unlike descriptive statistics, which summarize data, inferential statistics go beyond the data at hand to estimate parameters, test hypotheses, and predict future trends.
This article delves into the definition of inferential statistics, its types, methods, and practical examples, offering insights into how it supports decision-making in various fields.

Inferential Statistics
Inferential statistics involves techniques used to infer characteristics of a population based on sample data. It relies on probability theory to evaluate the reliability and generalizability of these inferences.
Key Characteristics of Inferential Statistics:
- Generalization: Extends conclusions from a sample to a population.
- Hypothesis Testing: Evaluates claims or predictions about a population.
- Estimation: Provides parameter estimates (e.g., population mean, proportion) using sample statistics.
- Uncertainty Measurement: Quantifies confidence and error margins.
Example: Using a survey of 500 people to estimate the voting preferences of an entire city’s population.
Importance of Inferential Statistics
- Informed Decision-Making: Provides evidence-based predictions and insights.
- Efficient Analysis: Draws conclusions without studying the entire population.
- Supports Research: Facilitates hypothesis testing and model building.
- Addresses Variability: Accounts for random variation and sampling errors.
Types of Inferential Statistics
1. estimation.
- Description: Involves estimating population parameters (e.g., mean, proportion) using sample data.
- Point Estimation: Provides a single value estimate (e.g., sample mean).
- Interval Estimation: Offers a range of values, often with a confidence interval.
- Example: Estimating the average income of a country based on a sample survey.
2. Hypothesis Testing
- Description: Tests assumptions or claims about a population parameter.
- Null Hypothesis (H₀): Assumes no effect or difference.
- Alternative Hypothesis (H₁): Proposes a specific effect or difference.
- Example: Testing whether a new drug is more effective than an existing treatment.
3. Regression Analysis
- Description: Examines relationships between dependent and independent variables.
- Linear Regression: Models linear relationships.
- Multiple Regression: Considers multiple predictors simultaneously.
- Example: Predicting house prices based on size, location, and number of rooms.
4. Analysis of Variance (ANOVA)
- Description: Compares means across multiple groups to identify significant differences.
- Example: Testing whether three teaching methods produce different student outcomes.
5. Correlation Analysis
- Description: Measures the strength and direction of relationships between variables.
- Example: Analyzing the correlation between study time and test scores.
6. Chi-Square Tests
- Description: Examines relationships or associations between categorical variables.
- Example: Testing whether gender and job preference are independent of each other.
Methods of Inferential Statistics
1. sampling techniques.
- Simple Random Sampling: Each individual has an equal chance of selection.
- Stratified Sampling: Population divided into strata, with samples taken from each.
- Systematic Sampling: Every nth individual in the population is selected.
- Example: Sampling 100 households in a city to estimate average water consumption.
2. Probability Distributions
- Normal Distribution: Bell-shaped curve; central in statistical analyses.
- Binomial Distribution: Models outcomes with two possible results (e.g., success/failure).
- Example: Using a normal distribution to model exam scores.
3. Confidence Intervals
- Description: Provides a range within which a population parameter is expected to lie with a specified confidence level (e.g., 95%).
- Example: Stating that the average income is $50,000 ± $2,000 at a 95% confidence level.
4. Hypothesis Testing Procedures
- State null and alternative hypotheses.
- Choose significance level (e.g., 0.05).
- Perform a statistical test (e.g., t-test, z-test).
- Interpret p-value and decide whether to reject H₀.
- Example: Testing whether students score better after implementing a new curriculum.
5. Statistical Tests
- T-Test: Compares means between two groups.
- F-Test: Compares variances or more than two group means.
- Chi-Square Test: Evaluates relationships between categorical variables.
Examples of Inferential Statistics
1. healthcare research.
- Objective: Test the effectiveness of a new vaccine.
- Method: Conduct clinical trials on a sample of patients.
- Outcome: Infer vaccine efficacy for the entire population based on sample results.
2. Marketing Analysis
- Objective: Predict customer preferences.
- Method: Use regression analysis on survey data.
- Outcome: Estimate the likelihood of customers buying a product based on their demographics.
3. Environmental Studies
- Objective: Assess air quality in a city.
- Method: Sample air pollution levels at specific locations.
- Outcome: Infer overall air quality trends for the city.
4. Educational Research
- Objective: Determine the impact of a new teaching method.
- Method: Use ANOVA to compare test scores across three different classrooms.
- Outcome: Identify significant differences in learning outcomes.
Advantages of Inferential Statistics
- Generalization: Allows conclusions about a population based on a smaller sample.
- Hypothesis Testing: Facilitates evaluation of research questions and claims.
- Predictive Insights: Enables forecasting future trends or outcomes.
- Flexibility: Applicable across various disciplines and research scenarios.
Limitations of Inferential Statistics
- Sampling Errors: Results may not be accurate if the sample is not representative.
- Dependence on Assumptions: Requires assumptions like normality, which may not always hold.
- Complexity: Statistical tests and models can be challenging for non-experts.
- Risk of Misinterpretation: Misuse or misunderstanding of p-values or confidence intervals can lead to incorrect conclusions.
Tips for Effective Use of Inferential Statistics
- Choose the Right Test: Match the statistical method to your research question and data type.
- Ensure Sample Representativeness: Use proper sampling techniques to reduce bias.
- Understand Assumptions: Verify that data meets the assumptions of the chosen statistical method.
- Report Results Clearly: Include confidence intervals, p-values, and effect sizes for transparency.
- Combine with Context: Interpret statistical findings in the context of your research area.
Inferential statistics is a powerful tool for making predictions and drawing conclusions about a population based on sample data. By leveraging techniques like hypothesis testing, regression analysis, and ANOVA, researchers can uncover insights and support data-driven decisions across diverse fields. While its reliance on assumptions and potential for sampling errors pose challenges, careful application and interpretation of inferential statistics ensure its continued significance in scientific and practical endeavors.
- Gravetter, F. J., & Wallnau, L. B. (2020). Statistics for the Behavioral Sciences . Cengage Learning.
- Field, A. (2017). Discovering Statistics Using IBM SPSS Statistics . Sage Publications.
- Babbie, E. R. (2020). The Practice of Social Research . Cengage Learning.
- Trochim, W. M. K. (2021). The Research Methods Knowledge Base . Atomic Dog Publishing.
- Agresti, A. (2018). Statistical Methods for the Social Sciences . Pearson Education.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Methodological Framework – Types, Examples and...

Discourse Analysis – Methods, Types and Examples

MANOVA (Multivariate Analysis of Variance) –...

Histogram – Types, Examples and Making Guide

Content Analysis – Methods, Types and Examples

Correlation Analysis – Types, Methods and...
- How it works
"Christmas Offer"
Terms & conditions.
As the Christmas season is upon us, we find ourselves reflecting on the past year and those who we have helped to shape their future. It’s been quite a year for us all! The end of the year brings no greater joy than the opportunity to express to you Christmas greetings and good wishes.
At this special time of year, Research Prospect brings joyful discount of 10% on all its services. May your Christmas and New Year be filled with joy.
We are looking back with appreciation for your loyalty and looking forward to moving into the New Year together.
"Claim this offer"
In unfamiliar and hard times, we have stuck by you. This Christmas, Research Prospect brings you all the joy with exciting discount of 10% on all its services.
Offer valid till 5-1-2024
We love being your partner in success. We know you have been working hard lately, take a break this holiday season to spend time with your loved ones while we make sure you succeed in your academics
Discount code: RP0996Y
Your content here...

Inferential Statistics – Guide With Examples
Published by Jamie Walker at August 25th, 2021 , Revised On December 12, 2022
Statistics students must have heard a lot of times that inferential statistics is the heart of statistics. Well, that is true and reasonable. While descriptive statistics are easy to comprehend, inferential statistics are pretty complex and often have different interpretations.
If you are also confused about how descriptive and inferential statistics are different, this blog is for you. Everything from the definition of inferential statistics to its examples and uses is all mentioned here.
Having that said, let’s start with where statistics initially came from.
Inferential Statistics: An Introduction
To know the origin and definition of inferential statistics, you must know what statistics is and how it came to be.
So, statistics is the branch of math that deals with collecting, assessing, and interpreting data. It includes how this data is presented in the form of numbers and digits. In other words, statistics is the study of quantitative or numerical data.
Statistics is broadly divided into two departments, namely Applied Statistics and Theoretical Statistics. Applied Statistics are further categorized into two sub-groups: Descriptive Statistics and Inferential Statistics.
There are two main areas of Inferential Statistics:
- Estimating Parameters: It means taking a statistic from a sample and utilizing it to describe something about a population .
- Hypothesis Testing : it is when you use this sample data to answer various research questions .
Now let’s delve down deeper and see how descriptive and inferential statistics are different from each other.
Inferential Statistics vs. Descriptive Statistics
Descriptive statistics allow you to explain a data set, while inferential statistics allow you to make inferences or interpretations based on a particular data set.
Here are a few differences between inferential and descriptive statistics:
Firstly , descriptive statistics can be used to describe a particular situation, while inferential statistics are used to dig deeper into the chances of occurrence of a condition.
Secondly , descriptive statistics give information about raw data and how it is organized in a particular manner. The other one, on the contrary, compares data and helps you make predictions and hypotheses with it.
Lastly , descriptive statistics are shown with charts, graphs, and tables, while inferential statistics are achieved via probability. Descriptive statistics have a diagrammatic or tabular representation of the final outcomes, and inferential statistics show results in the probability form.
Are we clear about the differences between these two? Let move on to the next topic then.
Sampling Error and Inferential Statistics
Can you recall the sample and population? How about statistics and parameters? Great, if you can.
Here is a quick recap for those who cannot remember these terms.
Sample: A sample is a small group taken from the population to observe and draw conclusions. Population: It is the entire group under study. Statistic: A statistic is a number that describes a sample. For instance, the sample mean. Parameter: It is a number that describes the whole population. For instance, a population mean.
Why should you use a Plagiarism Detector for your Paper?
It ensures:
- Original work
- Structure and Clarity
- Zero Spelling Errors
- No Punctuation Faults

The fact that the size of the sample is much smaller than that of a population, there is a great chance that some of the population is not captured by the sample data. Hence, there is always room for error, which we call sampling error in statistics. It is the difference between the true population values and the captured population values. In other words, it is the difference between parameters and statistics.
A sampling error can occur any time you examine a sample, regardless of the sampling technique, i.e., random or systematic sampling. This is why there is some uncertainty in inferential statistics, no matter what. However, this can be reduced using probability sampling methods.
You can make two kinds of estimates about the population:
Point Estimate -it is a single value estimate of a population parameter.
Interval Estimate -it gives you a wide range of values where the parameter is predicted to lie.
Have you heard of a confidence interval? That is the most used type of interval estimate.
Details are below:
Confidence Intervals
Confidence intervals tend to use the variability around a sample statistic to deduce an interval estimate for a parameter. They are used for finding parameters because they assess the sampling errors. For instance, if a point estimate reflects a precise value for the population parameter, confidence intervals give you an estimate of the uncertainty of the point estimate.
All these confidence intervals are associated with confidence levels that tell you about the probability of the interval containing the population parameter estimate on repeating the study.
An 85 percent confidence interval means that if you repeat the research with a new sample precisely the same way 100 times, you can predict the estimate to lie within the range of values 85 times.
You might expect the estimate to lie within the interval a certain percentage of the time, but you cannot be 100% confident that the actual population parameter will. It is simply because you cannot predict the true value of the parameter without gathering data from the whole population.
However, with suitable sample size and random sampling, you can expect the confidence interval to contain the population parameter a certain percentage of the time.
Hypothesis Testing and Inferential Statistics
Hypothesis testing is a practice of inferential statistics that aims to deduce conclusions based on a sample about the whole population. It allows us to compare different populations in order to come to a certain supposition.
These hypotheses are then tested using statistical tests , which also predict sampling errors to make accurate inferences. Statistical tests are either parametric or non-parametric. Parametric tests are thought to be more powerful from a statistics point of view, as they can detect an existing effect more likely.
Some of the assumptions parametric tests make are:
- Sample of a population follows a normal distribution of scores
- The sample size is big enough to represent the whole the population
- A measure of the spread of all groups compared are same
Non-parametric tests are not effective when the data at hand violates any of the assumptions mentioned above. The fact that non-parametric tests do not assume anything about the population distribution they are called “distribution-free tests.”
Forms of Statistical Tests
The statistical tests can be of three types or come in three versions:
Comparison Tests
Correlation Tests
Regression Tests
As the name suggests, comparison tests evaluate and see if there are differences in means and medians . They also assess the difference in rankings of scores of two or multiple groups.
The correlation tests allow us to determine the extent to which two or more variables are associated with each other.
Lastly, the regression tests tell whether the changes in predictor variables are causing changes in the outcome variable or not. Depending on the number and type of variables you have as outcomes and predictors, you can decide which regression test suits you the best.
FAQs About Inferential Statistics
1. what are the two main branches of statistics.
Statistics is broadly divided into two departments, namely Applied Statistics, and Theoretical Statistics. Applied Statistics are further categorized into two sub-groups: Descriptive Statistics and Inferential Statistics.
2. What are inferential statistics?
They help us compare data and make predictions with it. Inferential statistics allow you to assess a test hypothesis and see whether data is generating the whole population or not.
3. What are statistics and parameters?
Statistic: A statistic is a number that defines a sample. For instance, the sample mean .
Parameter: It is a number that describes the whole population. For instance, a population mean.
4. Define sampling error.
It is the difference between the true population values and the captured population values.
5. What are the three forms of statistical tests?
The correlation tests allow us to find out the extent to which two or more variables are associated with each other.
The regression tests tell whether the changes in predictor variables are causing changes in the outcome variable or not.
6. What is hypothesis testing?
Hypothesis testing is a kind of inferential statistics that aims to deduce conclusions based on samples about the whole population. It allows us to compare different populations in order to come to a certain supposition.
You May Also Like
A dependent variable is one that completely depends on another variable, mostly the independent one.
Effect size in statistics measures how important the difference between group means and the relationship between different variables.
A variable is an attribute to which different values can be assigned. The value can be a characteristic, a number, or a quantity that can be counted. It is sometimes called a data item.
As Featured On

USEFUL LINKS
LEARNING RESOURCES

COMPANY DETAILS

Splash Sol LLC
- How It Works
Inferential Statistics: Making Predictions from Data
- March 21, 2024
- Neural Ninja

Table of Contents
I. introduction to inferential statistics, unveiling the power of inferential statistics: an overview.
Inferential statistics stand at the crossroads of data analysis, offering a bridge from the concrete to the predictive, from what we know to what we can infer. It’s a realm where data transforms into decisions, where raw numbers morph into actionable insights. But what exactly propels this transformation? Inferential statistics, in its essence, employs mathematical models, assumptions, and logic to deduce the properties of a larger population from a smaller sample. This is akin to tasting a spoonful of soup to predict the flavor of the entire pot. It’s both an art and a science, leveraging probability to make educated guesses about the unknown, based on the known.
The Critical Role of Inferential Statistics in Data-Driven Decision Making
In today’s era, where data is ubiquitously hailed as the new oil, inferential statistics acts as the refinery that turns crude data into fuel for decision-making. Whether in business strategies, healthcare prognosis, or environmental policies, it plays a pivotal role. But why is it so indispensable? The answer lies in its ability to help us make sense of complex, often incomplete, datasets. By understanding the probable characteristics of a broader group, organizations can tailor their approaches to better meet consumer needs, predict market trends, and navigate through uncertainties with a higher degree of confidence.
From Observation to Prediction: The Journey of Data Analysis
Embarking on the journey from observation to prediction is like setting sail from the shores of the known, guided by the stars of statistical inference, towards the horizons of future possibilities. This voyage begins with the collection and understanding of descriptive statistics, which paint a picture of our immediate data landscape. Yet, to navigate further, we harness the power of inferential statistics, moving beyond describing what is, to forecasting what could be. This progression is not just about numbers; it’s a fundamental shift towards anticipating outcomes, preparing for trends, and making informed decisions that shape the future.
By standing on the shoulders of the descriptive statistics groundwork laid before, inferential statistics allows us to leap into the realm of prediction and strategic foresight. It’s a toolkit for the curious, the forward-thinkers, and the decision-makers, empowering them to see beyond the horizon.
As we prepare to dive deeper into the world of inferential statistics, remember, this journey is about connecting the dots between data and decisions. It’s about unlocking the stories hidden within numbers and translating them into pathways for action. Stay tuned as we explore the core concepts, practical applications, and ethical considerations that guide our hand as we chart the course through the data-driven waters of the modern world.
II. Understanding the Foundations of Inferential Statistics
Population vs. sample: grasping the basics.
Imagine you’re at a beach looking at the ocean. You can’t possibly drink all the water to know if it’s salty, right? Instead, you taste a drop and infer about the entire ocean. Similarly, in inferential statistics, we have:
- Population : The entire ocean, representing all possible data or outcomes we’re interested in.
- Sample : The drop of ocean water, a subset of the population used for analysis.
Why does this matter? Well, analyzing the whole population is often impractical, expensive, or outright impossible. By carefully selecting a sample, we can make predictions about the population without examining every single part of it.
Key Points :
- A population includes every member of a group (e.g., all students in a school).
- A sample is a portion of the population selected for analysis (e.g., 100 students from the school).
Table 1: Population vs. Sample
Sampling Methods: Ensuring Representativeness and Minimizing Bias
To ensure our sample accurately represents the population, we must be mindful of sampling methods . There are two main types:
- Simple Random Sampling : Everyone has an equal chance of being chosen.
- Stratified Sampling : The population is divided into subgroups (strata), and random samples are taken from each.
- Convenience Sampling : Selecting individuals who are easily accessible.
- Judgmental Sampling : The researcher chooses based on their judgment.
Why Sampling Method Matters : The right method helps avoid bias , where certain group characteristics are over or underrepresented, potentially skewing results.
Table 2: Sampling Methods
The Concept of Distribution: Normalcy and Its Importance
When we talk about distribution , we’re looking at how our data is spread out or arranged. The Normal Distribution , also known as the Bell Curve , is a key concept here.
Characteristics :
- Symmetrical around the mean.
- Most data points cluster around the mean, with fewer points further away.
Why It’s Important : Many statistical tests assume normal distribution because it’s a common pattern in many natural phenomena and human behaviors. Knowing whether your data follows this distribution helps in selecting the right inferential statistical methods.
Table 3: Understanding Normal Distribution
Inferential statistics, building on these foundational concepts, allows us to extrapolate insights from our sample to the broader population, making informed decisions and predictions. As we venture further, keeping these basics in mind will enhance our understanding and application of more complex statistical techniques.
III. Core Concepts in Inferential Statistics
Estimation: point estimates and confidence intervals explained.
Breaking Down Estimation
In the world of inferential statistics, estimation acts as a guide, helping us approximate the true characteristics of a population from a sample. This process is essential for making predictions about larger groups based on observed data.
- Point Estimate : This is a specific value that serves as our best guess about a population parameter, derived from our sample. For example, if we calculate the average height of 50 trees and find it to be 20 feet, this average is our point estimate of the average height of all trees in the area.
- Confidence Interval : Recognizing that our point estimate is based on a sample, we use a confidence interval to express the degree of uncertainty or certainty in our estimate. It’s a range around our point estimate that likely contains the true population parameter.
Illustration : Consider estimating the average reading time for articles on your blog. If the average reading time for a sample of articles is 7 minutes, with a confidence interval of 6 to 8 minutes, this range suggests a high level of confidence that the true average time falls within these bounds.
- Point Estimate : A precise estimate (e.g., 7 minutes average reading time).
- Confidence Interval : A range indicating where the true average likely falls (e.g., 6 to 8 minutes).
Table 4: Understanding Estimation
Hypothesis Testing: The Framework for Making Inferences
Unraveling Hypothesis Testing
Hypothesis testing is a systematic method used to determine the validity of a hypothesis about a population based on sample data. It’s the statistical equivalent of conducting an experiment to support or refute a theory.
- Null Hypothesis (H₀) : This represents a default stance that there is no effect or difference. For example, “Interactive elements have no impact on reading time.”
- Alternative Hypothesis (H₁) : Represents a claim to be tested, suggesting an effect or difference exists. Example: “Interactive elements increase reading time.”
Decision Making : Through hypothesis testing, we analyze sample data to determine if it significantly deviates from what the null hypothesis would predict. This analysis helps us decide whether to reject H₀ in favor of H₁.
Table 5: Hypothesis Testing Overview
p-Values and Significance Levels: Interpreting the Language of Data
Decoding p-Values
A p-value quantifies the probability that the observed data (or more extreme) could occur under the null hypothesis. It’s a tool for measuring the strength of evidence against H₀.
- Low p-value (< 0.05) : Indicates strong evidence against the null hypothesis, suggesting our findings are unlikely due to chance alone.
- High p-value (≥ 0.05) : Indicates weak evidence against the null hypothesis, suggesting our findings might be due to random variation.
Significance Levels (α) : The predetermined threshold we set to decide when to reject H₀. Commonly set at 0.05, it represents the risk level we’re willing to take in mistakenly rejecting the null hypothesis.
Table 6: p-Values and Decisions
IV. Practical Applications of Inferential Statistics
Inferential statistics play a pivotal role in shaping decisions and strategies across various sectors. By drawing insights from sample data, organizations can predict outcomes and make informed decisions. Below, we explore real-world applications of inferential statistics, moving beyond hypothetical examples to demonstrate their tangible impact.
Real-World Business Strategy: Netflix’s Use of Data Analytics
Driving Decisions with Data
Netflix’s use of big data and inferential statistics to personalize viewer recommendations is a prime example of data-driven decision-making. By analyzing vast datasets on viewer preferences, Netflix employs complex algorithms to predict and suggest shows and movies that you’re likely to enjoy, significantly enhancing user experience and retention.
Key Takeaways:
- Customization at Scale : Leveraging viewer data allows Netflix to tailor content recommendations, keeping users engaged.
- Strategic Content Acquisition : Data insights inform Netflix’s decisions on which shows to buy or produce, optimizing their investment in content.
Predicting Trends in Healthcare: The Case of Google Flu Trends
Early Warning Systems
Google Flu Trends was an initiative by Google to predict flu outbreaks based on search query data related to flu symptoms. While it faced challenges in accuracy over time, the project highlighted the potential of using inferential statistics and big data to predict public health trends, informing public health responses and resource allocation.
Insights and Learnings:
- Innovative Surveillance : Demonstrated the potential for using search data as a complement to traditional flu surveillance methods.
- Adaptation and Accuracy : The need for continual refinement of predictive models to maintain reliability.
Environmental Policy Evaluation: Deforestation and Climate Change
Data-Driven Policy Making
Research using inferential statistics has significantly contributed to understanding the impact of deforestation on climate change. Studies utilizing satellite data and statistical models have provided evidence that supports policy initiatives aimed at reducing deforestation and mitigating climate change, guiding international agreements and national policies.
Sustainable Impact:
- Evidence-Based Policies : Empirical data on deforestation’s effects informs global environmental policies.
- Targeted Interventions : Statistical analysis helps identify critical areas for conservation efforts, maximizing the impact of resources allocated for environmental protection.
V. Diving Deeper: Advanced Techniques in Inferential Statistics
In our journey through the world of inferential statistics, we’ve laid the groundwork with core concepts and practical applications. Now, let’s venture further into the statistical deep, exploring advanced techniques that unlock even more insights from our data. These tools not only enhance our understanding but also empower us to make even more precise predictions.
Regression Analysis: Predicting Outcomes and Understanding Relationships
A Glimpse into Regression Analysis
Regression analysis stands as a cornerstone in the realm of inferential statistics, offering a powerful way to predict outcomes and explore the relationships between variables. Think of it as detective work, where you’re piecing together clues (data points) to solve a mystery (understand your data’s story).
- What It Does : At its heart, regression helps us understand how the typical value of a dependent (target) variable changes when one or more independent (predictor) variables are altered. It’s like observing how the amount of rainfall affects plant growth.
- Types of Regression : While there are several types, linear and logistic regressions are most common. Linear regression predicts a continuous outcome (e.g., sales volume), while logistic regression is used for binary outcomes (e.g., win or lose).
Table 7: Key Regression Terms
Example : Imagine a small business trying to forecast next month’s sales based on their advertising budget. Using regression analysis, they can identify the strength of the relationship between spending on ads and sales outcomes, helping them allocate their budget more effectively.
ANOVA: Analyzing Variance for Deeper Insights
Unlocking Insights with ANOVA
ANOVA, or Analysis of Variance, lets us compare the means of three or more groups to see if at least one differs significantly. Picture you’re a chef experimenting with different ingredients to find the perfect recipe. ANOVA helps you determine which ingredient variations truly impact the dish’s taste.
- Purpose : It’s particularly useful when you’re dealing with multiple groups and want to understand if there’s a real difference in their means.
- Applications : From marketing campaigns to clinical trials, ANOVA aids in decision-making by identifying which variables have the most significant effect on the outcome.
Table 8: Understanding ANOVA
Real-World Application : Consider a tech company testing three different website designs to see which one leads to the highest user engagement. By applying ANOVA, they can statistically conclude whether the design differences significantly affect engagement rates.
Chi-Square Tests: Assessing Categorical Data
Exploring Relationships with Chi-Square Tests
The Chi-Square test is our go-to statistical tool for examining the relationship between categorical variables. Imagine you’re sorting marbles by color and size into boxes; the Chi-Square test helps you determine if there’s a pattern or just random distribution.
- Purpose : It’s best used when you want to see if there’s an association between two categorical variables (like gender and purchase preference).
- How It Works : The test compares the observed frequencies in each category against what we would expect to see if there was no association between the variables.
Table 9: Chi-Square Test at a Glance
Scenario : A bookstore wants to know if reading preferences differ by age group. By categorizing their sales data (observed frequencies) and using the Chi-Square test, they can uncover meaningful patterns, tailoring their stock to cater to different age groups more effectively.
VI. Interactive Learning Session: Hands-On with Inferential Statistics
Guided tutorial: deep dive into inferential statistics with python.
Dataset Overview: The Wine dataset contains the results of a chemical analysis of wines grown in the same region in Italy but derived from three different cultivars. The analysis determined the quantities of 13 constituents found in each of the three types of wines. Our objective is to use inferential statistics to understand the differences between the wine types.
Learning Outcomes:
- Estimate population parameters based on sample data.
- Conduct hypothesis tests to compare wine types.
- Perform ANOVA to examine the differences across multiple groups.
Pre-requisites: Ensure Python is installed along with numpy , scipy , matplotlib , pandas , and sklearn . These libraries are necessary for data analysis and visualization.
Comprehensive Python Code for Inferential Analysis:
Dataset Insights:
Upon loading the dataset, we observed diverse chemical compositions across 178 wine samples, categorized into three types. Initial examination provided us with a peek into the dataset’s structure, revealing attributes like alcohol content, malic acid, ash, and others. This preliminary step is crucial for understanding the data we’re working with, setting the stage for deeper analysis.
Statistical Summary:
The basic statistical details gave us an overview of the dataset’s characteristics, including means, standard deviations, and ranges for each chemical constituent. This summary not only aids in identifying potential outliers but also in assessing the data distribution across different wine types.
Inferential Statistics in Action:
- We estimated the mean alcohol content for each wine type, finding notable differences among them. Specifically, Type 0 wines had a higher average alcohol content (13.74%) compared to Type 1 (12.28%) and Type 2 (13.15%). This suggests that Type 0 wines are generally stronger in alcohol compared to Type 1, with Type 2 presenting a middle ground.
- A t-test comparing the alcohol content between wine types 0 and 1 yielded a significant result (T-statistic = 16.48, P-value ≈ 0). The extremely low p-value indicates a strong statistical significance, allowing us to reject the null hypothesis. This means there is a statistically significant difference in alcohol content between these wine types, corroborating our initial observation from the mean estimates.
- The ANOVA test further expanded our analysis to compare the means of alcohol content across all three wine types. The results (F-value = 135.08, P-value ≈ 0) strongly suggest significant differences in alcohol content among the wine types. The near-zero p-value confirms that these differences are statistically significant, not likely due to random chance.
Visualization: Alcohol Content Distribution by Wine Type:
The boxplot visualization provided a clear, intuitive representation of the distribution of alcohol content across the wine types. It visually confirmed the findings from our statistical tests, showcasing the variability and helping us identify which wine types are stronger or milder in alcohol content.
Concluding Insights:
Our journey through inferential statistics with the Wine dataset illuminated the power of statistical analysis in drawing meaningful conclusions from sample data. The significant differences in alcohol content among wine types underscore the value of hypothesis testing and ANOVA in uncovering hidden patterns and distinctions within datasets.
Engaging with Data: A Call to Action:
Armed with these insights and the practical experience of analyzing the Wine dataset, you’re encouraged to explore further. Experiment with other chemical constituents like malic acid or flavonoids to uncover more about what sets these wine types apart. Each analysis you conduct is a step forward in honing your inferential statistics skills and enhancing your ability to make informed predictions and decisions based on data.
As we conclude this interactive learning session, remember that the realm of data science is vast and filled with opportunities for discovery. Whether you’re analyzing wine, weather patterns, or web traffic, the principles of inferential statistics remain a powerful guide in your data analysis journey.
VII. Incorporating Inferential Statistics in Machine Learning
From statistical inference to predictive modeling: bridging the gap.
Machine Learning (ML) represents the pinnacle of applying inferential statistics to predictive analytics, embodying the transition from traditional statistical inference to dynamic, predictive modeling. This evolution marks a shift from merely understanding data retrospectively to forecasting future trends and behaviors with precision.
Foundational Concepts:
- Statistical Inference forms the bedrock of ML, underpinning algorithms with the statistical rigor necessary for making reliable predictions. It involves using sample data to make inferences about the broader population, much like the foundational practices of inferential statistics.
- Predictive Modeling in ML extends this principle, utilizing algorithms to process and analyze vast datasets, thereby predicting future events or behaviors based on identified patterns.
Key Components:
- Data Preprocessing: Critical for model accuracy, involving cleaning, transforming, and splitting data into training and testing sets.
- Model Selection: Involves choosing the right algorithm based on the nature of the data and the prediction task (e.g., regression, classification).
- Training and Validation: Models are trained on a subset of data and validated using cross-validation techniques to ensure robustness and prevent overfitting.
Table 10: Bridging Inferential Statistics and ML
Evaluating Model Performance: The Role of Statistical Tests
Evaluating the performance of ML models is imperative to ensure their predictive reliability and validity. Statistical tests play a crucial role in this evaluation process, providing a framework for objectively assessing model accuracy, precision, and overall effectiveness.
Performance Metrics:
- Accuracy: The proportion of correct predictions made by the model overall predictions.
- Precision and Recall: Precision measures the accuracy of positive predictions, while recall (sensitivity) measures the ability to identify all actual positives.
- F1 Score: Harmonic mean of precision and recall, providing a single metric to assess the model balance between precision and recall.
Statistical Tests in Model Evaluation:
- T-tests and ANOVA: Compare model performances to ascertain statistical significance in differences, useful in algorithm selection and hyperparameter tuning.
- Chi-Square Tests: Assess the independence of categorical variables, valuable in feature selection and understanding model inputs.
- Regression Analysis: Evaluates the relationship between variables, offering insights into the impact of different features on model predictions.
Table 11: Statistical Tests for Model Evaluation
Incorporating inferential statistics into ML not only bridges the gap between traditional statistics and predictive modeling but also enhances the interpretability and reliability of ML models. By rigorously evaluating model performance using statistical tests, practitioners can make informed decisions, ensuring models are both accurate and applicable to real-world scenarios.
This approach underscores the importance of statistical foundations in the ever-evolving field of machine learning, ensuring that as we advance technologically, our methods remain rooted in robust, scientific principles. As we continue to harness the power of data through ML, the principles of inferential statistics will remain central to unlocking the potential of predictive analytics, guiding us toward more accurate, reliable, and insightful decision-making processes.
VIII. Ethics and Considerations in Inferential Statistics
Data privacy and ethical use: navigating the grey areas.
In the evolving landscape of data-driven decision-making, ethics, particularly around data privacy and usage, emerge as pivotal concerns. As we delve into inferential statistics, we’re often handling sensitive information that can have real-world impacts on individuals and communities. The ethical use of data isn’t just about legal compliance; it’s about fostering trust and ensuring the dignity and rights of all stakeholders are respected.
Key Ethical Considerations:
- Consent and Transparency: Individuals should be informed about what data is being collected, how it will be used, and whom it will be shared with. This is not just about fulfilling legal obligations but about building a foundation of trust.
- Anonymity and Confidentiality: When using data for statistical analysis, it’s crucial to anonymize datasets to protect individual identities. Techniques such as data masking or pseudonymization can help safeguard personal information.
- Fair Use: Data should be used in ways that do not harm or disadvantage individuals or groups. This includes being mindful of biases that might be present in the data or introduced during analysis.
Table 12: Ethical Practices in Data Use
Interpretation and Misinterpretation: Avoiding Common Pitfalls
The power of inferential statistics lies in its ability to draw conclusions about populations from sample data. However, this power comes with the responsibility to interpret results accurately and convey findings clearly. Misinterpretation can lead to misguided decisions, potentially with significant consequences.
Common Pitfalls:
- Overgeneralization: Drawing broad conclusions from a sample that may not be representative of the entire population can lead to overgeneralized and inaccurate insights.
- Ignoring Margin of Error: Every estimate in inferential statistics comes with a margin of error. Ignoring this can give a false sense of precision.
- Confusing Correlation with Causation: Just because two variables are correlated does not mean one causes the other. This is a common mistake that can lead to incorrect assumptions about relationships between variables.
Strategies for Accurate Interpretation:
- Contextual Analysis: Always interpret statistical findings within the context of the study, including considering potential confounding variables.
- Clear Communication: When presenting statistical results, clearly explain the significance levels, confidence intervals, and any assumptions or limitations of the analysis.
- Peer Review: Encourage scrutiny and validation of findings through peer review to catch errors or oversights.
Table 13: Strategies for Accurate Data Interpretation
Incorporating Ethics and Responsibility
As we journey further into the world of inferential statistics, embracing ethical considerations and striving for accurate interpretation are not just optional; they are imperative. These practices are the bedrock upon which trust in data science is built. By adhering to ethical guidelines and approaching data interpretation with care, we not only safeguard privacy and ensure fairness but also enhance the credibility and impact of our analyses.
Remember, behind every data point is a human story. As we use inferential statistics to uncover patterns and predict trends, let’s commit to doing so with integrity and respect for those stories. This commitment will not only enrich our understanding of the data but also strengthen the bond of trust between data scientists and the communities they serve.
IX. Realizing the Full Potential of Inferential Statistics
Innovative uses of inferential statistics in technology and science.
Inferential statistics is not just a set of mathematical tools; it’s the compass that guides us through the vast sea of data, revealing insights and guiding decisions. As we delve into its innovative uses, particularly in technology and science, we uncover its transformative power across various fields.
1. Enhancing Precision Medicine:
- Overview: Medical researchers use inferential statistics to analyze genetic data from patients, identifying patterns that predict disease susceptibility and treatment outcomes.
- Impact: Tailored treatment plans for individuals, improving efficacy and minimizing side effects.
2. Advancing Artificial Intelligence (AI) and Machine Learning (ML):
- Application: From customer behavior predictions in e-commerce to anticipating machinery failures in manufacturing, inferential statistics underpin algorithms making these forecasts possible.
- Outcome: Increased efficiency, reduced costs, and improved customer experiences.
3. Environmental Conservation Efforts:
- Insight: By applying inferential statistics to climate data, scientists can model future climate patterns, aiding in the formulation of more effective conservation policies.
- Result: Better preparedness and targeted environmental conservation strategies.
4. Societal Trends and Public Policy:
- Application: Inferential statistics are used to analyze survey data, helping policymakers understand public opinion on various issues.
- Effectiveness: Policies and initiatives that are more closely aligned with public needs and values.
5. Space Exploration:
- Example: Statistical models predict the best launch windows and optimal pathways for space missions, increasing success rates and reducing risks.
- Achievement: Enhanced exploration capabilities and deeper understanding of our universe.
The Future of Data Analysis: Emerging Trends and Technologies
The future of inferential statistics is intertwined with the evolution of data analysis technologies. Emerging trends promise to expand our capabilities, making data analysis more intuitive, predictive, and impactful.
1. Integration with Big Data Technologies:
- Trend: The increasing use of big data technologies enables the analysis of vast datasets in real-time, allowing for more dynamic and precise inferential statistics.
- Future Impact: Real-time decision-making and forecasting in business, healthcare, and environmental management.
2. Augmented Analytics:
- Advancement: Leveraging AI and ML to automate data preparation and analysis, augmented analytics make inferential statistics more accessible to non-experts.
- Potential: Democratizing data analysis, enabling more organizations and individuals to make data-driven decisions.
3. Quantum Computing:
- Innovation: Quantum computing promises to revolutionize data analysis by performing complex statistical calculations at unprecedented speeds.
- Expectation: Solving previously intractable problems in science, engineering, and finance.
4. Ethical AI and Bias Mitigation:
- Focus: As inferential statistics fuel AI and ML models, there’s a growing emphasis on ethical AI and the development of techniques to identify and mitigate biases in data analysis.
- Vision: Fairer, more accurate models that reflect the diversity and complexity of the real world.
5. Personalized Learning and Development:
- Application: Inferential statistics power personalized learning platforms, adapting content and teaching methods to individual learners’ needs.
- Promise: More effective and engaging learning experiences, with potential applications in education, professional development, and beyond.
X. Conclusion
Summing up: the impact and importance of inferential statistics.
In our comprehensive journey through the realms of inferential statistics, we’ve seen how it serves as the backbone of decision-making in our increasingly data-driven world. Inferential statistics, with its ability to make predictions about larger populations from smaller samples, unlocks the door to informed decisions, strategy formulation, and the anticipation of future trends across various domains—from healthcare to environmental policy, and from business strategies to technological innovations.
This branch of statistics does not merely crunch numbers; it tells us stories hidden within data, it forecasts possibilities, and it guides actions with a foundation in logical and mathematical reasoning. By understanding the intricacies of sample data, we’re equipped to make predictions with a notable degree of confidence, thereby reducing uncertainty in our decisions and strategies.
Moreover, the integration of inferential statistics with machine learning and predictive modeling showcases the evolving landscape of data analysis. This synergy is paving the way for advancements in precision medicine, AI, and even our understanding of climate change, emphasizing the transformative power of data when analyzed with inferential statistical methods.
Your Path Forward: Continuing Education and Resources for Advanced Learning
Embracing inferential statistics is not the end of your data analysis journey; it’s a gateway to deeper exploration and continuous learning. As we stand on the brink of technological and scientific frontiers, the importance of staying updated and honing your skills in inferential statistics cannot be overstated. Here are ways to propel your knowledge and expertise further:
- Engage with Continuing Education : Pursue advanced courses and certifications that delve deeper into inferential statistics and its applications in machine learning, data science, and beyond.
- Practical Application : Apply what you’ve learned by working on real-world projects or datasets. Platforms like Kaggle or GitHub offer a treasure trove of opportunities to test your skills.
- Stay Curious : Always question and look beyond the data presented. Inferential statistics is as much about the questions you ask as the answers you find.
XI. Resources for Further Exploration
Books, online courses, and platforms: expanding your knowledge in inferential statistics.
To continue your journey in inferential statistics and related fields, immerse yourself in a mix of foundational texts, cutting-edge research, and interactive learning platforms. Here are some resources to guide your path:
- “ The Signal and the Noise ” by Nate Silver: A fascinating look at prediction in various fields, emphasizing statistical thinking.
- “ Naked Statistics ” by Charles Wheelan: Makes statistical concepts accessible to everyone, focusing on how they apply in our daily lives.
- Coursera and edX offer courses from leading universities on inferential statistics, data science, and machine learning, catering to various skill levels.
- DataCamp and Codecademy provide interactive coding exercises that emphasize hands-on learning of statistical analysis and data science.
- Kaggle : Engage with a global community of data scientists and statisticians, participate in competitions, and explore datasets.
- Stack Overflow and Cross Validated (Stack Exchange): Ideal for asking questions, sharing knowledge, and learning from a community of experts.
Joining the Conversation: Forums and Communities for Data Enthusiasts
Immerse yourself in the vibrant community of data enthusiasts. Forums and online communities offer invaluable opportunities to exchange ideas, seek advice, and share discoveries. Consider joining:
- LinkedIn Groups and Reddit communities focused on data science, statistics, and machine learning. These platforms host a wealth of discussions, job postings, and networking opportunities.
- Data Science Central and Towards Data Science on Medium: Platforms that feature articles, insights, and tutorials from data science professionals and enthusiasts.
By integrating these resources and communities into your learning journey, you not only enhance your knowledge but also connect with like-minded individuals passionate about data and its potential to shape the future.
QUIZ: Test Your Knowledge!
Quiz summary.
0 of 27 Questions completed
Information
You have already completed the quiz before. Hence you can not start it again.
Quiz is loading…
You must sign in or sign up to start the quiz.
You must first complete the following:
Quiz complete. Results are being recorded.
0 of 27 Questions answered correctly
Time has elapsed
You have reached 0 of 0 point(s), ( 0 )
Earned Point(s): 0 of 0 , ( 0 ) 0 Essay(s) Pending (Possible Point(s): 0 )
- Not categorized 0%
- Review / Skip
1 . Question
What is the purpose of inferential statistics?
- A. To describe data patterns
- B. To make predictions about a population based on a sample
- C. To summarize data
- D. To visualize data distributions
2 . Question
What is the main role of inferential statistics in data-driven decision making?
- A. To confuse data patterns
- B. To complicate data analysis
- C. To help make sense of complex datasets
- D. To ignore statistical assumptions
3 . Question
What does the Normal Distribution represent?
- A. A distribution with no mean
- B. A distribution that is skewed to one side
- C. A symmetrical distribution around the mean
- D. A distribution with no variability
4 . Question
What is the purpose of Confidence Interval in inferential statistics?
- C. To express the degree of uncertainty or certainty in an estimate
5 . Question
What is the Null Hypothesis in hypothesis testing?
- A. Suggests an effect or difference exists
- B. Represents a default stance that there is no effect or difference
- C. Is always the correct hypothesis
- D. Is irrelevant in statistical analysis
6 . Question
What does a low p-value indicate in hypothesis testing?
- A. Strong evidence against the null hypothesis
- B. Weak evidence against the null hypothesis
- C. Strong evidence for the null hypothesis
- D. No evidence for or against the null hypothesis
7 . Question
What is the purpose of ANOVA in inferential statistics?
- A. To compare means of three or more groups
- B. To analyze relationships between variables
- C. To assess categorical data
- D. To calculate confidence intervals
8 . Question
What does the Chi-Square test assess in inferential statistics?
- A. Relationships between variables
- B. Means of multiple groups
- C. Independence of categorical variables
- D. Confidence intervals
9 . Question
What is regression analysis used for in inferential statistics?
- A. Analyzing variance
- B. Assessing categorical data
- C. Predicting outcomes and understanding relationships
- D. Comparing means of groups
10 . Question
What is the significance of ethical considerations in data analysis?
- A. They complicate the analysis process
- B. They are optional practices
- C. They are imperative for building trust and respecting privacy
- D. They are irrelevant in data analysis
11 . Question
What is the main role of inferential statistics in machine learning?
- B. To make predictions about the past
- C. To enhance the interpretability and reliability of ML models
- D. To ignore data patterns
12 . Question
What is the purpose of integrating inferential statistics with machine learning?
- A. To complicate data analysis
- B. To enhance the interpretability and reliability of ML models
- C. To avoid statistical tests
- D. To confuse data patterns
13 . Question
What does ethical AI focus on in data analysis?
- A. Creating biased models
- B. Identifying and mitigating biases in data analysis
- C. Ignoring ethical considerations
- D. Disregarding privacy concerns
14 . Question
What is the significance of statistical tests in evaluating ML model performance?
- A. They complicate the evaluation process
- B. They are irrelevant in model evaluation
- C. They provide a framework for objectively assessing model accuracy
- D. They are only used for data visualization
15 . Question
What is the key benefit of integrating inferential statistics into machine learning?
- A. To ignore data patterns
16 . Question
What is the main focus of ethical considerations in data use?
- B. Ensuring privacy and fairness in data analysis
- C. Ignoring ethical guidelines
- D. Disregarding data privacy concerns
17 . Question
What is the primary purpose of Confidence Interval in inferential statistics?
- B. To express the degree of uncertainty or certainty in an estimate
- C. To ignore statistical assumptions
- D. To complicate data analysis
18 . Question
What is the role of ANOVA in inferential statistics?
- A. To analyze relationships between variables
- B. To compare means of three or more groups
19 . Question
20 . question, 21 . question, 22 . question, 23 . question, 24 . question, 25 . question, 26 . question, 27 . question.
Related Posts

Descriptive Statistics: Understanding the Basics
I. Introduction to Descriptive Statistics The Essence of Descriptive Statistics in Data Analysis Imagine you’re a detective, but instead of solving mysteries in dark alleys, you’re unraveling the stories hidden within data. This is the essence of descriptive statistics –

Mastering Data Analysis: Transform Raw Data into Powerful Insights
I. Introduction to the Journey of Data Analysis From Intuition to Informed Decisions: The Evolution of Decision-Making Embracing Data in Our Daily Lives In today’s world, data surrounds us everywhere. From choosing the fastest route home to deciding what to

What is Data Analysis and Why it Matters?
I. Introduction to Data Analysis Welcome to the world of Data Analysis! Imagine you’re a detective, but instead of solving crimes, you solve puzzles with numbers and facts. That’s what data analysts do every day, and it’s becoming more and
© Let’s Data Science
Unlock AI & Data Science treasures. Log in!
Only fill in if you are not human
- Onsite training
3,000,000+ delegates
15,000+ clients
1,000+ locations
- KnowledgePass
- Log a ticket
01344203999 Available 24/7

Inferential Statistics: A Comprehensive Introduction
Inferential Statistics is a branch of statistics that allows researchers to make conclusions and predictions regarding a population based on data collected from a sample. This blog is a comprehensive exploration of Inferential Statistics that encompasses its importance, types, and examples. Continue reading to learn more!

Exclusive 40% OFF
Training Outcomes Within Your Budget!
We ensure quality, budget-alignment, and timely delivery by our expert instructors.
Share this Resource
- Introduction to Business Analytics Training
- Statistical Process Control Training
- Probability and Statistics for Data Science Training
- Mathematical Optimisation for Business Problems

Picture the power to uncover hidden patterns, make predictions and have a confident peek into the future - all from a sample of data! This is made possible by Inferential Statistics. This branch of statistics empowers researchers to make bold conclusions about a population based on a data sample. From testing hypotheses to crafting confidence intervals, this field can teach you the art of drawing insightful conclusions.
This blog takes you on a journey through the world of Inferential Statistics, exploring its types, examples and more. So, read on and achieve statistical mastery in data-driven decision-making!
Table of Contents
1) What is Inferential Statistics?
2) Different Types of Inferential Statistics
3) Inferential Statistics Examples
4) Differences Between Inferential Statistics and Descriptive Statistics
5) Conclusion
What is Inferential Statistics?
Inferential statistics is a powerful field of statistics that uses analytical tools to draw conclusions about a population through the examination of random samples. The prime goal of inferential statistics is to make generalisations about a population. In this field, a statistic is taken from the sample data (the sample mean) that is used to make inferences about the population parameter (the population mean).

Different Types of Inferential Statistics
Inferential statistics consists of several techniques for drawing conclusions, including confidence testing, regression analysis and hypothesis testing. Let's explore them in detail

1) Hypothesis Testing
Hypothesis testing is a fundamental technique for testing a hypothesis about a population parameter (e.g., a mean) using sample data. This process involves these two steps:
a) Setting up alternative or null hypotheses
b) Conducting a statistical test to determine whether there's reasonable evidence for rejecting the null hypothesis in favour of the alternative hypothesis.
Example: A researcher might hypothesise that the average income of people in a certain city is more than £40,000 per year. Then, a sample of incomes will be collected and a hypothesis test will be conducted. This will help the researcher determine whether the data provides enough evidence to support or reject this hypothesis.
2) Confidence Intervals
Confidence intervals provide a broad range of values within which a population parameter lies and a level of confidence associated with the range. They are used to estimate a population parameter's true value based on sample data. The confidence interval's width depends on the sample size and the desired confidence level.
Example: A poller may use a confidence interval to estimate the voter proportion who supports a particular candidate. It would provide a range of values within which the proportion of supporters is likely to lie, along with a confidence level such as 85%.
Want to gain expertise in forecasting future business outcomes? Sign up for our Introduction t o Business Analytics Training now!
3) Regression Analysis
Regression analysis evaluates the relationship between one (or more) independent variables and a dependent variable. It can:
a) Predict the dependent variable's value based on the values of the independent variables.
b) Allow for testing hypotheses regarding the strength of relationships between variables.
Example: A researcher can use regression analysis to examine the relationship between exam scores and hours of study. They can then use the regression model to make predictions about exam scores based on the hours studied.

4) Analysis of Variance (ANOVA)
ANOVA is a technique for comparing means across two or more groups. It analyses whether there are any statistically significant differences among the groups' means. To determine if observed differences were caused by chance or they represent true differences between groups, ANOVA calculates:
a) Between-group variance (variation between the group means)
b) Within-group variance (variation within each group)
Example: Researchers can use ANOVA to compare the effectiveness of various teaching methods on student performance. They could collect student performance data in each group and use ANOVA to determine whether there are any significant differences in performances between the groups.
5) Chi-square Tests
Chi-square tests help determine whether there's a significant association between two categorical variables. They compare the data's observed frequency distribution to the expected frequency distribution under null hypothesis of independence.
Example: A researcher can utilise a chi-square test to examine whether there is a relationship between voting preference and gender. They would collect data from a sample of voters and determine whether gender and voting preference are independent.
Master the craft of designing Statistical Process Control (SPC) systems in our comprehensive Statistical Process Control Course - Sign up now!
Inferential Statistics Examples
Here are two examples of the usage of inferential statistics:
1) Education: Let's say a researcher collects data on the SAT scores of 12th graders in a school for four years. They utilise descriptive statistics to receive a quick overview of the school’s scores within those years. Then, the mean SAT score can be compared with the mean scores of other schools.
2) Corporate Sector: Let's say a researcher wants to learn about the average number of paid vacation days that a company's employees receive. Following the collection of survey responses from a random sample, they calculate a point estimate and confidence interval. Point estimate of the mean paid vacation days is the sample mean of 18 paid vacation days. Through random sampling, a 95% confidence interval of [16 21] means that the average number of vacation days can be confidently stated to be between 16 and 21.
3) Medical Research: Let's say a pharmaceutical company is in the testing phase of a new drug. They collect a sample of 1,000 volunteers to participate in a clinical trial, out of which 750 reported a significant reduction in their symptoms after consuming the drug. Using inferential statistics, the company can infer that the drug is likely to be effective for the larger population.
Differences Between Inferential Statistics and Descriptive Statistics
The following table summarises the key distinctions between inferential statistics and descriptive statistics:

Conclusion
In conclusion, inferential statistics serves as a reliable bridge between sample data and broader insights into the population. Techniques like hypothesis testing and confidence intervals empower researchers to make informed predictions and data-driven decisions. As detailed in this blog, embracing this tool will enhance your understanding of data and its implications in diverse fields.
Master the essential techniques for optimising business decision-making in our Mathematical Optimisation f or Business Problems - Sign up now!
Frequently Asked Questions
Inferential statistics enables us to generalise findings from a sample to a broader population. This is especially useful when it’s impractical to collect data from every member of the population.
The key purposes of Inferential statistics include:
a) Generalisation of findings from a sample
b) Hypothesis Testing
c) Estimation on population parameters
d) Prediction s based on current data trends
The Knowledge Academy takes global learning to new heights, offering over 30,000 online courses across 490+ locations in 220 countries. This expansive reach ensures accessibility and convenience for learners worldwide.
Alongside our diverse Online Course Catalogue, encompassing 19 major categories, we go the extra mile by providing a plethora of free educational Online Resources like News updates, Blogs , videos, webinars, and interview questions. Tailoring learning experiences further, professionals can maximise value with customisable Course Bundles of TKA .
The Knowledge Academy’s Knowledge Pass , a prepaid voucher, adds another layer of flexibility, allowing course bookings over a 12-month period. Join us on a journey where education knows no bounds.
The Knowledge Academy offers various Business Analyst Courses , including the Business Process Mapping Training and the Statistical Process Control Course . These courses cater to different skill levels, providing comprehensive insights into Descriptive Statistics .
Our Business Analysis Blogs cover a range of topics related to statistics , offering valuable resources, best practices, and industry insights. Whether you are a beginner or looking to advance your statistics skills, The Knowledge Academy's diverse courses and informative blogs have got you covered.
Upcoming Business Analysis Resources Batches & Dates
Fri 21st Feb 2025
Fri 25th Apr 2025
Fri 20th Jun 2025
Fri 22nd Aug 2025
Fri 17th Oct 2025
Fri 19th Dec 2025
Get A Quote
WHO WILL BE FUNDING THE COURSE?
My employer
By submitting your details you agree to be contacted in order to respond to your enquiry
- Business Analysis
- Lean Six Sigma Certification
Share this course
Biggest christmas sale.

We cannot process your enquiry without contacting you, please tick to confirm your consent to us for contacting you about your enquiry.
By submitting your details you agree to be contacted in order to respond to your enquiry.
We may not have the course you’re looking for. If you enquire or give us a call on 01344203999 and speak to our training experts, we may still be able to help with your training requirements.
Or select from our popular topics
- ITIL® Certification
- Scrum Certification
- ISO 9001 Certification
- Change Management Certification
- Microsoft Azure Certification
- Microsoft Excel Courses
- Explore more courses
Press esc to close
Fill out your contact details below and our training experts will be in touch.
Fill out your contact details below
Thank you for your enquiry!
One of our training experts will be in touch shortly to go over your training requirements.
Back to Course Information
Fill out your contact details below so we can get in touch with you regarding your training requirements.
* WHO WILL BE FUNDING THE COURSE?
Preferred Contact Method
No preference
Back to course information
Fill out your training details below
Fill out your training details below so we have a better idea of what your training requirements are.
HOW MANY DELEGATES NEED TRAINING?
HOW DO YOU WANT THE COURSE DELIVERED?
Online Instructor-led
Online Self-paced
WHEN WOULD YOU LIKE TO TAKE THIS COURSE?
Next 2 - 4 months
WHAT IS YOUR REASON FOR ENQUIRING?
Looking for some information
Looking for a discount
I want to book but have questions
One of our training experts will be in touch shortly to go overy your training requirements.
Your privacy & cookies!
Like many websites we use cookies. We care about your data and experience, so to give you the best possible experience using our site, we store a very limited amount of your data. Continuing to use this site or clicking “Accept & close” means that you agree to our use of cookies. Learn more about our privacy policy and cookie policy cookie policy .
We use cookies that are essential for our site to work. Please visit our cookie policy for more information. To accept all cookies click 'Accept & close'.
- Skip to main content
- Skip to primary sidebar
- Skip to footer
- QuestionPro

- Solutions Industries Gaming Automotive Sports and events Education Government Travel & Hospitality Financial Services Healthcare Cannabis Technology Use Case AskWhy Communities Audience Contactless surveys Mobile LivePolls Member Experience GDPR Positive People Science 360 Feedback Surveys
- Resources Blog eBooks Survey Templates Case Studies Training Help center
Home Market Research
Inferential Statistics: Definition, Types, Formulas, Example

If you are a student in a statistics class or a professional researcher, you need to know how to use inferential statistics to analyze data and make smart decisions. In this age of “big data,” when we have access to a lot of information, the capacity to draw correct population conclusions from samples is crucial.
Inferential statistics enable you to draw inferences and make predictions based on your data, whereas descriptive statistics summarize the properties of a data collection. It is an area of mathematics that enables us to identify trends and patterns in a large number of numerical data.
In this post, we will discuss inferential statistics, including what they are, how they work, and some examples.
Definition of Inferential Statistics
Inferential statistics uses statistical techniques to extrapolate information from a smaller sample to make predictions and draw conclusions about a larger population.
It uses probability theory and statistical models to estimate population parameters and test population hypotheses based on sample data. The main goal of inferential statistics is to provide information about the whole population using sample data to make the conclusions drawn as accurate and reliable as possible.
There are two primary uses for inferential statistics:
- Providing population estimations.
- Testing theories to make conclusions about populations.
Researchers can generalize a population by utilizing inferential statistics and a representative sample. It requires logical reasoning to reach conclusions. The following is a procedure of the method for arriving at the results:
- The population to be investigated should be chosen as a sample. The sample should reflect the population’s nature and characteristics.
- Inferential statistical techniques are used to analyze the sample’s behavior. These include the models used for regression analysis and hypothesis testing.
- The first-step sample is used to draw conclusions. Inferences are drawn using assumptions or predictions about the entire population.
Types of Inferential Statistics
Inferential statistics are divided into two categories:
- Hypothesis testing.
- Regression analysis.
Researchers frequently employ these methods to generalize results to larger populations based on small samples. Let’s look at some of the methods available in inferential statistics.
01. Hypothesis testing
Testing hypotheses and drawing generalizations about the population from the sample data are examples of inferential statistics. Creating a null hypothesis and an alternative hypothesis, then performing a statistical test of significance are required.
A hypothesis test can have left-, right-, or two-tailed distributions. The test statistic’s value, the critical value, and the confidence intervals are used to conclude. Below are a few significant hypothesis tests that are employed in inferential statistics.
When data has a normal distribution and a sample size of at least 30, the z test is applied to the data. When the population variance is known, it determines if the sample and population means are equal. The following setup can be used to test the right-tailed hypothesis:
Null Hypothesis: H 0 : μ=μ 0
Alternate hypothesis: H 1 : μ>μ 0
Test Statistic: Z Test = (x̄ – μ) / (σ / √n)
x̄ = sample mean
μ = population mean
σ = standard deviation of the population
n = sample size
Decision Criteria: If the z statistic > z critical value, reject the null hypothesis.
When the sample size is less than 30, and the data has a student t distribution, a t test is utilized. The sample and population mean are compared when the population variance is unknown. The inferential statistics hypothesis test is as follows:
Alternate Hypothesis: H 1 : μ>μ 0
Test Statistic: t = x̄−μ / s√n
The representations x̄, μ, and n are the same as stated for the z-test. The letter “s” represents the standard deviation of the sample.
Decision Criteria: If the t statistic > t critical value, reject the null hypothesis.
When comparing the variances of two samples or populations, an f test is used to see if there is a difference. The right-tailed f test can be configured as follows:
Null Hypothesis: H 0 :σ 2 1 =σ 2 2
Alternate Hypothesis: H 1 :σ 2 1 > σ 2 2
Test Statistic: f = σ 2 1 / σ 2 2 , where σ 2 1 is the variance of the first population, and σ 2 2 is the variance of the second population.
Decision Criteria: Deciding Criteria: Reject the null hypothesis if f test statistic > critical value.
A confidence interval aids in estimating a population’s parameters. For instance, a 95% confidence interval means that 95 out of 100 tests with fresh samples performed under identical conditions will result in the estimate falling within the specified range. A confidence interval formula can also be used to determine the crucial value in hypothesis testing.
In addition to these tests, inferential statistics also use the ANOVA, Wilcoxon signed-rank, Mann-Whitney U, Kruskal-Wallis, and H tests.
LEARN ABOUT: ANOVA testing
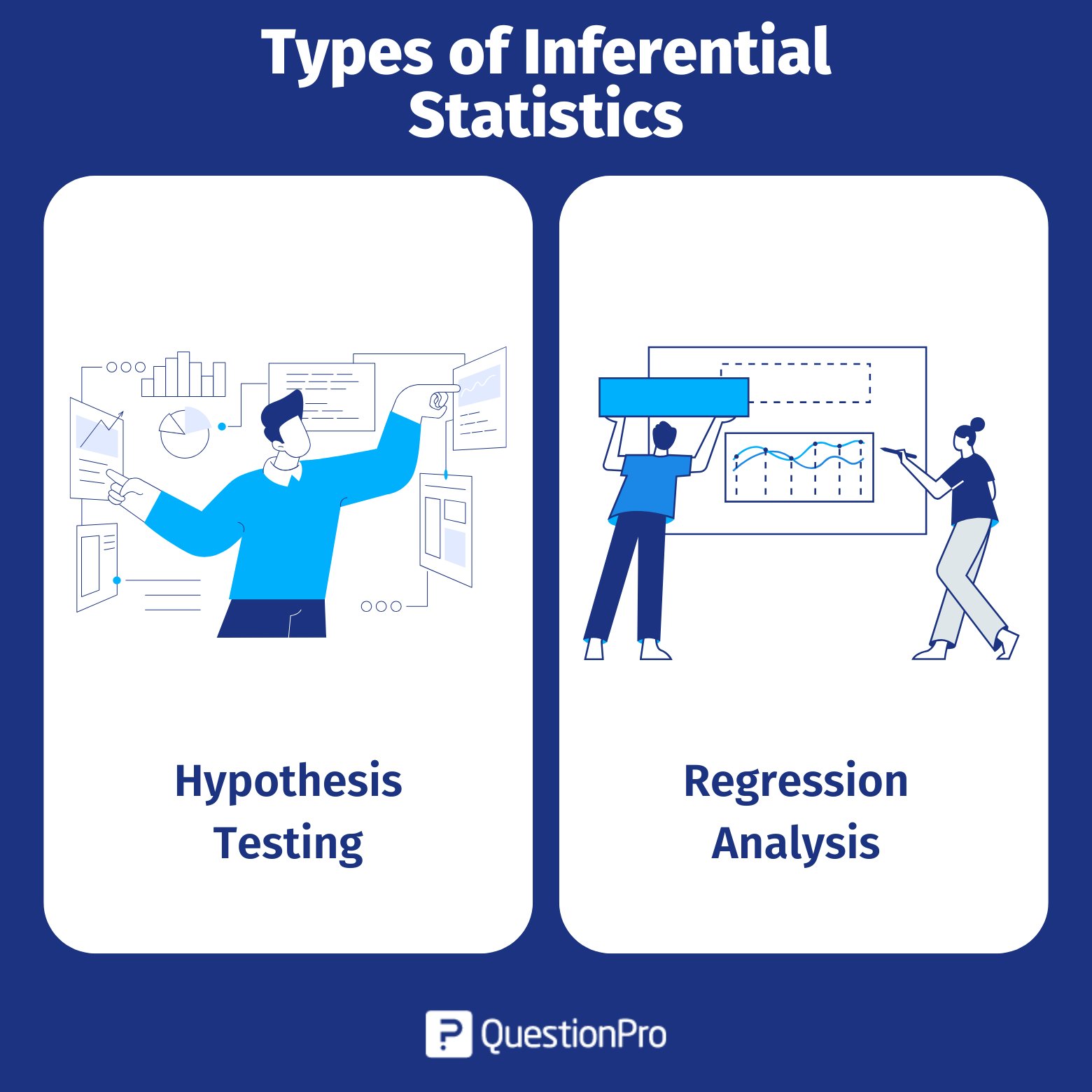
02. Regression analysis
Regression analysis calculates how one variable will change to another. Numerous regression models can be used, including simple linear, multiple linear, nominal, logistic, and ordinal regression.
In inferential statistics, linear regression is the most often employed type of regression. The dependent variable’s response to a unit change in the independent variable is examined through linear regression. These are a few crucial equations for regression analysis using inferential statistics:
Regression Coefficients:
The straight line equation is given as y = α + βx, where α and β are regression coefficients.
β=∑ n 1 (x i − x̄)(y i −y) / ∑ n 1 (x i −x) 2
β=r xy σ y / σ x
α=y−βx
Here, x is the mean, and σ x is the standard deviation of the first data set. Similarly, y is the mean, and σy is the standard deviation of the second data set.
Example of inferential statistics
Consider for this example that you based your research on the test results for a particular class as described in the descriptive statistics section. You now want to do an inferential statistics study for that same test.
Assume it is a standardized statewide exam. You may demonstrate how this alters how we perform the study and the results you report by using the same test, but this time to draw inferences about a community.
Choose the class you wish to describe in descriptive statistics, and then enter all the test results for that class. Good and easy. You must first define the population for inferential statistics before selecting a random sample from it.
To ensure a representative sample, you must develop a random sampling strategy. This procedure may take time. Let’s use fifth-graders attending public schools in the U.S. state of California as your population definition.
For this example, assume that you gave the entire population a list of names, then selected 100 students randomly from that list and obtained their test results. Be aware that these students will not be from a single class but rather a variety of classes from various schools throughout the state.
Inferential statistics results in
The mean, standard deviation, and proportion for your random sample can all be calculated using inferential statistics as a point estimate. There is no way to know, but it is unlikely that any of these point estimations are exact. These figures have a margin of error because measuring every subject in this population is impossible.
Include the confidence intervals for the mean, standard deviation, and percentage of satisfactory scores (>=70). The CSV data file contains inferential statistics.
The population mean is between 77.4 and 80.9, with a 95% confidence interval given the uncertainty around these estimates. A measure of dispersion, the population standard deviation is most likely to range between 7.7 and 10.1. Moreover, between 77% and 92% is predicted for the population’s proportion of satisfactory scores.
Differences between Descriptive and Inferential Statistics
Both descriptive and inferential statistics are types of statistical analysis used to describe and analyze data. Here are the main differences between them:
Descriptive statistics use measures like mean, median, mode, standard deviation, variance, and range to summarize and describe a data set’s characteristics. They don’t make conclusions or predictions about a population based on the data.
Inferential statistics , on the other hand, use a sample of data to draw conclusions about the population from which the data came. They use probability theory and statistical models to determine the likelihood of certain outcomes and test hypotheses about the population.
Descriptive statistics are usually used to summarize the data and explain the most important parts of the dataset clearly and concisely. They describe a variable’s distribution, find trends and patterns, and examine the relationship between variables.
Inferential statistics are usually used to test hypotheses and draw conclusions about a population from a sample. They are used to make predictions, estimate parameters, and test the importance of differences between groups.
Descriptive statistics can be used on any type of data, including numerical data (like age, weight, and height) and categorical data (e.g. gender, race, occupation).
Inferential statistics use random samples from a population and make assumptions about how the data are distributed and how big the sample is.
Descriptive statistics give an overview of the data and are usually shown in tables, graphs, or summary statistics.
Inferential statistics give estimates and probabilities about a population and are usually reported as hypothesis tests, confidence intervals, and effect sizes.
While inferential statistics are used to make inferences about the population based on sample data, descriptive statistics are used to summarize and characterize the data.
The Importance of Inferential Statistics: Some Remarks
- Inferential statistics uses analytical tools to determine what a sample’s data says about the whole population.
- Inferential statistics include things like testing a hypothesis and looking at how things change over time.
- Inferential statistics use sampling methods to find samples that are representative of the whole population.
- Inferential statistics uses tools like the Z test, the t-test, and linear regression to determine what is happening.
Inferential statistics is a powerful way to draw conclusions about whole groups of people based on data from a small sample. Inferential statistics uses probability sampling theory and statistical models to help researchers determine certain outcomes’ likelihood and test their ideas about the population. In statistical analysis, distinguishing between categorical data and numerical data is essential, as categorical data involves distinct categories or labels, while numerical data consists of measurable quantities.
Inferential statistics is an important part of the data unit of analysis and research because it lets us make predictions and draw conclusions about whole populations based on data from a small sample. It is a complicated and advanced field that requires careful thought about assumptions and data quality, but it can give important research questions and answers to important questions.
QuestionPro gives researchers an easy and effective way to collect and analyze data for inferential statistics. Its sampling options let you create a sample population representative of the larger population, and its data-cleaning tools help ensure the data is accurate.
QuestionPro is a helpful tool for researchers who need to collect and analyze data for inferential statistics. QuestionPro’s analytical features let you examine the relationships between variables, estimate population parameters, and test hypotheses. So sign up now!
LEARN MORE FREE TRIAL
MORE LIKE THIS

2024 QuestionPro Workforce Year in Review
Dec 23, 2024

QuestionPro Workforce Has All The Feels – Release of the New Sentiment Analysis
Dec 19, 2024

The Impact Of Synthetic Data On Modern Research

Companies are losing $ billions with gaps in market research – are you?
Dec 18, 2024
Other categories
- Academic Research
- Artificial Intelligence
- Assessments
- Brand Awareness
- Case Studies
- Communities
- Consumer Insights
- Customer effort score
- Customer Engagement
- Customer Experience
- Customer Loyalty
- Customer Research
- Customer Satisfaction
- Employee Benefits
- Employee Engagement
- Employee Retention
- Friday Five
- General Data Protection Regulation
- Insights Hub
- Life@QuestionPro
- Market Research
- Mobile diaries
- Mobile Surveys
- New Features
- Online Communities
- Question Types
- Questionnaire
- QuestionPro Products
- Release Notes
- Research Tools and Apps
- Revenue at Risk
- Survey Templates
- Training Tips
- Tuesday CX Thoughts (TCXT)
- Uncategorized
- What’s Coming Up
- Workforce Intelligence
Inferential Statistics: Definition, Types, Examples
November 7, 2024
Mohit Uniyal
Latest articles
Top 25 data science companies in india in 2025, a complete data science career guide, top 13 data science programming languages in 2025, difference between big data and data science, data science fundamentals, top 10 benefits of data science in 2025, what is data exploration a complete guide, locally weighted linear regression.
Statistics, a fundamental tool in data analysis, is divided into two main branches: descriptive statistics and inferential statistics . Descriptive statistics summarizes raw data through measures like mean, median, and standard deviation , offering a clear picture of what the data reveals. However, this method only describes the observed dataset without extending beyond it.
Inferential statistics goes further by making predictions and inferences about a larger population based on sample data. This branch of statistics plays a critical role in data-driven decision-making across industries by allowing analysts to generalize findings from limited datasets. It uses probability theories and sampling methods to provide insights beyond what is immediately observable.
The importance of inferential statistics lies in its ability to draw conclusions and test hypotheses, even when it’s impossible to analyze the entire population. This makes it essential in business forecasting, healthcare trials, and scientific research, where decision-making relies heavily on sound statistical inferences.
What is Inferential Statistics?
Inferential statistics is the branch of statistics used to draw conclusions and make predictions about a population based on data collected from a sample. This approach allows researchers and analysts to extend findings beyond the immediate dataset, providing insights that inform decisions about larger groups or phenomena. By applying probability theory , inferential statistics quantifies the uncertainty in predictions, offering a range of possible outcomes with a certain degree of confidence.
While descriptive statistics summarizes the main characteristics of a dataset, inferential statistics goes a step further by generalizing results to a population . For example, in a survey of 1,000 customers, descriptive statistics would summarize their satisfaction scores, while inferential statistics would use the sample data to estimate the satisfaction level of the entire customer base. This makes inferential statistics essential when it is impractical to collect data from the entire population.
The ability to make predictions and test hypotheses is critical across many fields. In business , companies use inferential statistics to forecast sales trends, evaluate marketing strategies, and optimize supply chain operations. Market researchers rely on it to understand customer preferences by analyzing survey samples. In healthcare , clinical trials use inferential methods to determine whether treatments are effective, ensuring that results from a sample group are applicable to the general population.
Inferential statistics plays an important role in scientific research , helping validate theories and hypotheses with statistical evidence. For example, researchers may test whether a new teaching method improves student performance by comparing the test results of a sample group with those of a control group. The insights generated from inferential statistics are essential in decision-making processes, ensuring that organizations and researchers can act on data even when working with incomplete information.
By extending findings from samples to entire populations, inferential statistics helps organizations manage risks, allocate resources effectively , and guide policy decisions with data-backed insights. This capability makes it indispensable in the modern data analytics landscape.
Types of Inferential Statistics
Inferential statistics encompasses various techniques that allow analysts to make predictions and generalizations about populations based on sample data. These methods are essential for drawing conclusions, testing hypotheses, and evaluating relationships between variables. The key types of inferential statistics include hypothesis testing, confidence intervals, regression analysis, analysis of variance (ANOVA) , and chi-square tests .
1. Hypothesis Testing
Hypothesis testing is a fundamental statistical method used to assess whether a particular assumption about a population parameter holds true. The process begins with the formulation of two hypotheses:
- Null Hypothesis (H₀) : Assumes no effect or difference exists.
- Alternative Hypothesis (H₁) : Contradicts the null hypothesis, suggesting an effect or difference.
The objective is to determine if the observed results are statistically significant or occurred by chance. Analysts use p-values to assess the strength of evidence against the null hypothesis, with a smaller p-value (e.g., < 0.05) indicating strong evidence to reject it.
Key Hypothesis Tests
- Z-Test : A Z-test is used when the population variance is known , and the sample size is large. It evaluates whether the means of two datasets differ significantly. Example : A company tests whether the average customer rating after a new product launch differs from the previous average rating.
- T-Test : A T-test is applied when the population variance is unknown or the sample size is small. It is commonly used to compare two means. Example : Comparing the average sales of two different stores to assess which location performs better.
- F-Test : An F-test compares the variances of two or more datasets and is often used in conjunction with ANOVA. Example : Determining if marketing campaigns with different budgets yield significantly different results.
2. Confidence Intervals
Confidence intervals provide a range within which a population parameter is likely to fall, given a specific confidence level (e.g., 95%). This interval gives analysts a sense of the precision of their estimates and the uncertainty associated with sample data.
Example of Calculating a Confidence Interval : A survey finds that 60% of customers prefer a product, with a margin of error of ±5% at a 95% confidence level. This means the true preference lies between 55% and 65% with 95% certainty.
Confidence intervals help businesses make informed predictions and support decision-making by quantifying the reliability of their estimates.
3. Regression Analysis
Regression analysis examines the relationship between dependent and independent variables , allowing analysts to predict outcomes. It is widely used in business to forecast trends and understand cause-and-effect relationships .
Example : A retail company uses regression analysis to predict future sales based on advertising spending. By understanding the impact of ad spending on sales, the business can allocate resources more efficiently.
Regression models also help identify key performance drivers and guide strategies by showing how changes in one variable affect another.
4. Analysis of Variance (ANOVA)
ANOVA is a statistical method used to compare the means of three or more groups to determine if significant differences exist between them. It helps identify whether a factor (e.g., a treatment or strategy) has a measurable effect across multiple groups.
Example : A company evaluates whether three different training programs result in varying levels of employee productivity. ANOVA determines if the differences in productivity are statistically significant, guiding future investments in employee development.
ANOVA is particularly useful in experiments where multiple conditions need to be compared simultaneously.
5. Chi-Square Tests
Chi-square tests are used to assess the relationships between categorical variables , helping analysts understand if observed distributions differ from expected ones. This method is commonly applied in fields like marketing and quality control .
Example : A retailer uses a chi-square test to determine whether customer preferences for a product differ significantly across different regions. If the preferences vary, the business can adjust its marketing strategies accordingly.
In manufacturing, chi-square tests ensure that defects occur randomly by comparing defect rates across production batches. This helps maintain product quality and identify areas for improvement.
Examples of Inferential Statistics
Market research.
In market research , inferential statistics helps companies understand customer preferences and predict future behavior based on sample surveys. Instead of collecting data from every customer, businesses gather responses from representative samples and generalize findings to their entire customer base. This allows companies to forecast trends and optimize marketing campaigns.
Example : A retail company surveys 1,000 customers to assess satisfaction with a new product. The results are used to estimate how satisfied the overall customer base is, guiding further product development or advertising strategies.
Medical Research
Inferential statistics plays a crucial role in clinical trials and medical research by evaluating the effectiveness of new treatments and drugs. Researchers test hypotheses by comparing the outcomes from sample groups receiving different treatments. The results are then generalized to predict how the treatment will perform in the broader population.
Example : A pharmaceutical company conducts a trial to determine the effectiveness of a new drug for reducing blood pressure. If the sample group shows significant improvement, researchers infer that the drug will likely benefit the general population.
Economists rely on inferential statistics to forecast trends, analyze economic data , and make policy recommendations. Using sample data, they develop models that predict future economic conditions, such as inflation or employment trends, which guide policymaking and investment decisions.
Example : An economic study gathers data on unemployment rates in several regions to predict national unemployment trends. Policymakers use these predictions to introduce measures aimed at stabilizing the job market.
Quality Control
In manufacturing, inferential statistics ensures product quality through sampling and hypothesis testing . Instead of inspecting every item in a batch, companies evaluate a representative sample to determine whether it meets quality standards. This approach identifies defects early, minimizing waste and ensuring high product quality.
Example : A car manufacturer tests a sample of 50 engines from a production batch to ensure they meet performance standards. If the sample passes, the company infers that the rest of the batch is also of high quality.
Educators use inferential statistics to assess student performance and learning outcomes . By analyzing test scores from sample groups, schools infer how well educational programs are working for the broader student population, guiding curriculum development and resource allocation.
Example : A school analyzes math test results from a group of 200 students to determine whether a new teaching method has improved performance across the entire grade.
Environmental Science
Environmental scientists apply inferential statistics to study environmental changes and predict future trends . Sampling methods allow researchers to monitor pollution levels, climate patterns, or biodiversity in specific regions and generalize findings to larger ecosystems.
Example : Researchers measure air quality in several cities to infer pollution trends at the national level. This data helps environmental agencies develop policies to reduce emissions and protect public health.
Inferential Statistics vs. Descriptive Statistics
Descriptive statistics and inferential statistics serve distinct roles in data analysis. Descriptive statistics focuses on summarizing raw data , providing insights into what the data shows. In contrast, inferential statistics goes beyond the sample data to make predictions or draw conclusions about a population .
Descriptive statistics offer clarity about existing data patterns , helping analysts summarize and present data in a comprehensible form. However, inferential statistics extends beyond the observed data , supporting decision-making by providing actionable insights and predictions. Both types are essential, with descriptive statistics often serving as the first step before applying inferential methods to analyze deeper patterns and relationships.
How Analysts Use Inferential Statistics in Decision-Making
Inferential statistics plays a crucial role in business and other decision-making processes by enabling analysts to draw insights from sample data. This statistical approach helps predict outcomes, evaluate risks, and optimize strategies , even when complete population data is unavailable. By using tools such as hypothesis testing, regression analysis, and confidence intervals , analysts make data-driven predictions that support critical business decisions.
One way inferential statistics supports decision-making is through forecasting and planning . Businesses use statistical models to predict future trends based on historical data. For example, retailers rely on sales forecasts generated from a sample of transactions to prepare for seasonal demand. Similarly, A/B testing helps companies determine the effectiveness of marketing campaigns by analyzing the behavior of sample groups.
In finance, inferential statistics assists in risk management and portfolio optimization . Analysts use statistical methods to predict market trends and assess the likelihood of financial risks. For example, they apply regression models to identify how macroeconomic factors affect stock prices, enabling informed investment decisions.
Healthcare organizations also benefit from inferential statistics by evaluating treatment effectiveness . Clinical trials use hypothesis tests to determine whether a new drug provides significant benefits compared to a placebo. This data helps healthcare providers make critical decisions about adopting new treatments.
The ability of inferential statistics to derive conclusions from limited data ensures that businesses and institutions can act strategically without needing to analyze every data point in a population. Whether optimizing marketing campaigns, managing risks, or planning resource allocation, analysts use inferential statistics to minimize uncertainty and guide decision-making effectively.
Importance of Inferential Statistics in a Data Science Career
Inferential statistics is a vital component of data science , playing a central role in model building, predictions, and decision-making . Data scientists use these techniques to analyze trends, validate hypotheses , and draw insights from sample datasets that represent larger populations. Knowledge of inferential statistics allows data scientists to build reliable models by estimating parameters and measuring the significance of variables.
In predictive analytics, data scientists rely on inferential statistics to make informed forecasts. For instance, regression models help predict customer churn, enabling companies to develop targeted retention strategies. Hypothesis testing is used to assess the significance of variables in machine learning models, ensuring that the most relevant factors are incorporated. Confidence intervals provide a measure of certainty, guiding decisions with a quantified understanding of uncertainty.
Key skills required for data scientists include proficiency in hypothesis testing, regression analysis, and statistical inference techniques . These skills allow them to evaluate models and validate results, ensuring that predictions are not based on chance. For example, data scientists conduct A/B testing to compare the impact of two product features, selecting the one that maximizes user engagement.
Inferential statistics also helps data scientists identify patterns in data and uncover hidden relationships, supporting tasks like customer segmentation and trend analysis . With these skills, data scientists can provide actionable insights that drive business strategies and operational improvements.
In today’s data-driven world, proficiency in inferential statistics ensures that data scientists can transform data into meaningful insights , guiding organizations toward better decision-making . It is a foundational skill that supports the development of robust predictive models and ensures that analytical outcomes align with real-world scenarios.
Inferential statistics plays a pivotal role in data analysis by enabling predictions and generalizations from sample data to larger populations. Throughout the article, we explored the core concepts, including hypothesis testing, confidence intervals, and regression analysis , as well as practical applications across industries such as business, healthcare, and economics .
The ability of inferential statistics to provide actionable insights ensures informed decision-making , even when complete data is unavailable. Whether used in forecasting trends or validating hypotheses, inferential statistics is a valuable tool for guiding strategies and minimizing uncertainty in today’s data-driven world. Mastery of these techniques is essential for making reliable predictions and achieving better outcomes.
References:
- Inferential Statistics – Definition, Types, Examples, Formulas
- Inferential Statistics | An Easy Introduction & Examples
Featured articles

December 19, 2024
Pruning in Machine Learning
Anshuman Singh

Learning Rate in Machine Learning

December 17, 2024
Goals of Artificial Intelligence
Team Applied AI
IMAGES
COMMENTS
Mar 25, 2024 · Inferential Statistics Topics. The role of inferential statistics in making population predictions. Comparing confidence intervals and hypothesis tests in statistical inference. Applications of inferential statistics in clinical trials. The importance of sample size in inferential analysis. The role of t-tests in comparing means between groups.
Mar 25, 2024 · Inferential statistics is a branch of statistics that uses sample data to make generalizations, predictions, or inferences about a larger population. Unlike descriptive statistics, which summarize data, inferential statistics go beyond the data at hand to estimate parameters, test hypotheses, and predict future trends.
Sep 4, 2020 · While descriptive statistics summarize the characteristics of a data set, inferential statistics help you come to conclusions and make predictions based on your data. When you have collected data from a sample, you can use inferential statistics to understand the larger population from which the sample is taken.
Statistics, Inferential. D.M. Scott, in International Encyclopedia of Human Geography, 2009. Inferential statistics is concerned with making inferences (decisions, estimates, predictions, or generalizations) about a population of measurements based on information contained in a sample of those measurements. The two basic types of statistical ...
Aug 25, 2021 · Now let’s delve down deeper and see how descriptive and inferential statistics are different from each other. Inferential Statistics vs. Descriptive Statistics. Descriptive statistics allow you to explain a data set, while inferential statistics allow you to make inferences or interpretations based on a particular data set.
Mar 21, 2024 · Research using inferential statistics has significantly contributed to understanding the impact of deforestation on climate change. Studies utilizing satellite data and statistical models have provided evidence that supports policy initiatives aimed at reducing deforestation and mitigating climate change, guiding international agreements and ...
Nov 26, 2024 · Inferential Statistics is a branch of statistics that allows researchers to make conclusions and predictions regarding a population based on data collected from a sample. This blog is a comprehensive exploration of Inferential Statistics that encompasses its importance, types, and examples.
Inferential statistics use statistical models to help you compare your sample data to other samples or to previous research. Most research uses statistical models called the Generalized Linear model and include Student’s t-tests , ANOVA (Analysis of Variance ), regression analysis and various other models that result in straight-line ...
Inferential statistics is an important part of the data unit of analysis and research because it lets us make predictions and draw conclusions about whole populations based on data from a small sample. It is a complicated and advanced field that requires careful thought about assumptions and data quality, but it can give important research ...
Nov 7, 2024 · Statistics, a fundamental tool in data analysis, is divided into two main branches: descriptive statistics and inferential statistics. Descriptive statistics summarizes raw data through measures like mean, median, and standard deviation, offering a clear picture of what the data reveals. However, this method only describes the observed dataset without extending beyond it. Inferential ...